2025 年开年,DeepSeek R1 跟 V3 重磅宣布,其超强的言语建模与推理才能,引爆了寰球 AI 社区。与此同时,一个暗藏在超年夜范围模子死后的技巧命题浮出水面:怎样让千亿参数超年夜范围 AI 模子真正到达贸易级推理速率?这一成绩的谜底,暗藏在推理引擎 SGLang 的代码堆栈中。该名目由 LMSYS Org 发动,并遭到 xAI、NVIDIA、AMD 等巨子的青眼,正在经由过程多项要害技巧冲破,从新界说 LLM 推理的效力界限。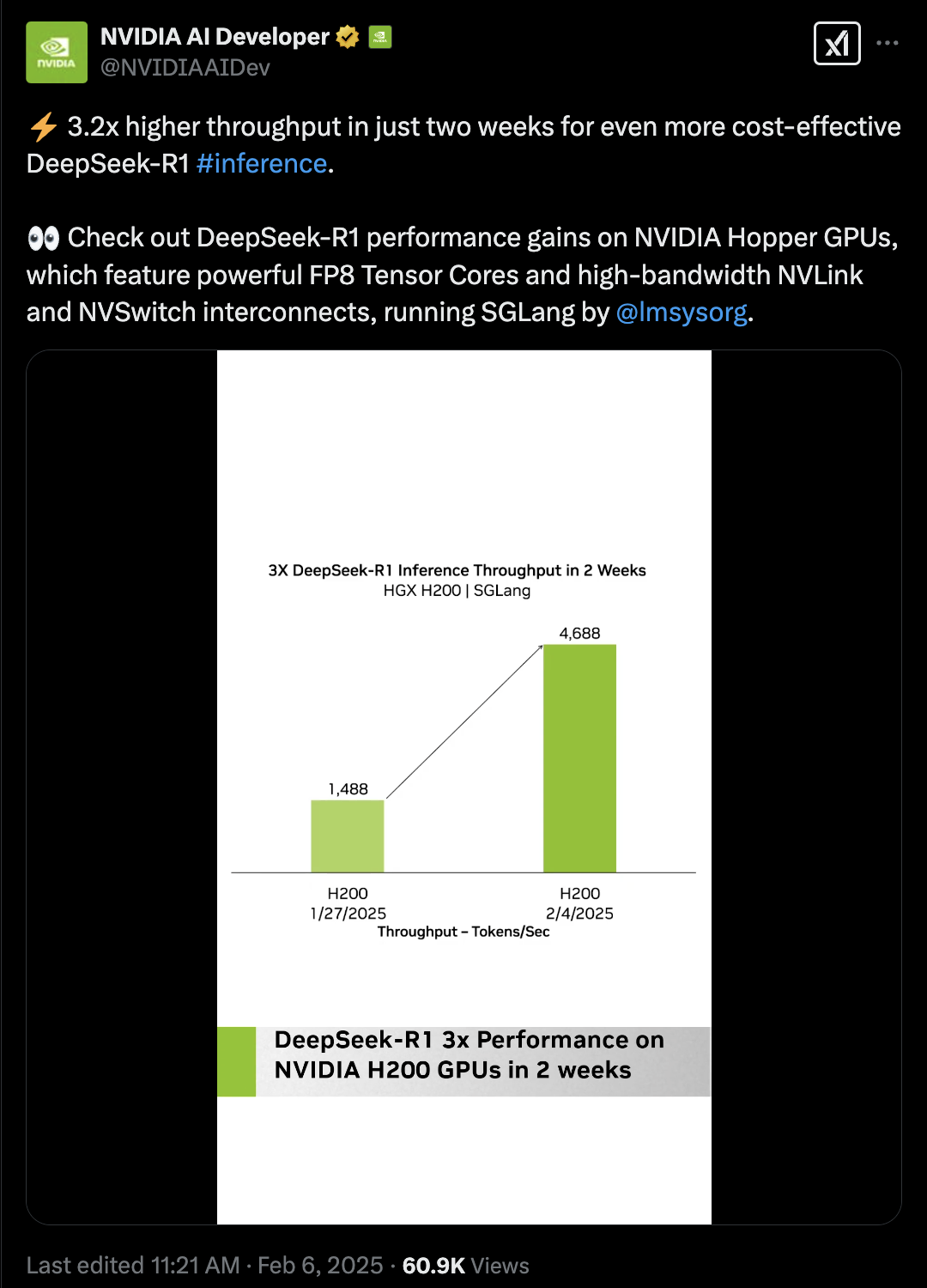 从 DeepSeek 模子宣布当天便实现最佳适配,到临时稳居 SOTA 机能榜首,SGLang 的退化轨迹提醒了一个开源名目的硬核生活法令:用工程翻新,霸占开辟者最辣手的机能瓶颈。经由过程当先的 Multi-head Latent Attention Optimzation、Data Parallelism Router、Eagle Speculative Decoding 等等技巧计划,SGLang 临时坚持开源模子顶尖的推理速率跟吞吐量。然而,SGLang 的征程毫不止步于此。当 Agent 的工程师们用其安排智能体时,当开辟者在 NVIDIA Triton 内核中融入其优化战略时,当全天下的研讨者高强度应用 DeepSeek 当地安排时,这个名目的真正代价正在浮现:它不只是临时当先的推理引擎,更是开源社区群体聪明的结晶。本文将从中心技巧冲破、体系级优化到开辟者生态,解码 SGLang 独到的退化之路。一、DeepSeek 模子连续优化,架构适配的工程实际
从 DeepSeek 模子宣布当天便实现最佳适配,到临时稳居 SOTA 机能榜首,SGLang 的退化轨迹提醒了一个开源名目的硬核生活法令:用工程翻新,霸占开辟者最辣手的机能瓶颈。经由过程当先的 Multi-head Latent Attention Optimzation、Data Parallelism Router、Eagle Speculative Decoding 等等技巧计划,SGLang 临时坚持开源模子顶尖的推理速率跟吞吐量。然而,SGLang 的征程毫不止步于此。当 Agent 的工程师们用其安排智能体时,当开辟者在 NVIDIA Triton 内核中融入其优化战略时,当全天下的研讨者高强度应用 DeepSeek 当地安排时,这个名目的真正代价正在浮现:它不只是临时当先的推理引擎,更是开源社区群体聪明的结晶。本文将从中心技巧冲破、体系级优化到开辟者生态,解码 SGLang 独到的退化之路。一、DeepSeek 模子连续优化,架构适配的工程实际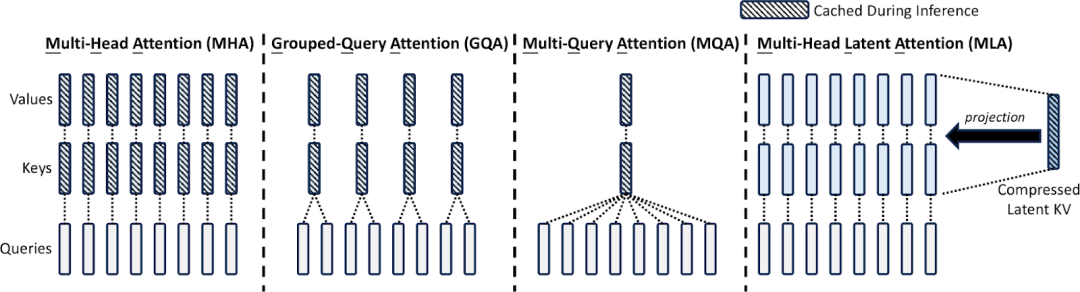 image credit: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model自从 DeepSeek V2 宣布以来,SGLang 团队针对 DeepSeek 系列模子的 MLA(Multi-head Latent Attention)架构停止了深度优化。这些技巧笼罩了数据并行留神力(Data Parallelism Attention)、多节点张量并行(Multi Node Tensor Parallelism)以及块级 FP8 量化(Block-wise FP8),从而在解码盘算、显存治理跟多节点协等同多个环节实现了冲破性晋升。对 Multi-head Latent Attention(MLA)的优化,团队经由过程应用权重接收从新陈列盘算步调,在保障模子表白才能的条件下,均衡了盘算与内存拜访负载,下降懂得码进程中的冗余盘算,下降了 MLA 在 Decode 进程中的盘算量。在此基本上,针对 MLA 解码核仅保存一个 KV 头的计划,SGLang 团队开辟了 Triton 解码核优化计划。该计划经由过程在统一盘算块内同时处置多个 query 头,明显增加了对 KV Cache 的内存拜访需要,从而减速懂得码流程。别的,团队联合 W8A8 FP8、KV Cache FP8 量化技巧,并开辟了 FP8 批量矩阵乘法(BMM)算子,实现了 MLA 高效的 FP8 推理。值得一提的是,MLA 与 Mixture-of-Experts(MoE)模块均已兼容 CUDA Graph 跟 Torch.compile,可能进一步下降小批量推理时的耽误。经由这些综合优化,DeepSeek 系列模子在输出吞吐率方面较上一版本实现了最高达 7 倍的减速后果。面临高并发跟大量量数据的现实利用需要,团队进一步在 MLA 留神力机制中引入了数据并行留神力技巧。该计划经由过程将差别范例的 batch(包含 prefill、decode、extend 以及 idle 状况)分辨调配给各个数据并行任务单位,使得各单位可能自力处置各自义务。待义务实现后,在 Mixture-of-Experts(MoE)层前后再停止须要的同步操纵,从而明显下降了 KV Cache 的反复存储累赘,优化了内存应用,并支撑更大量量恳求的高效处置。该优化专为高 QPS(Queries Per Second)场景计划,用户在应用 DeepSeek 系列模子时可经由过程下令参数 --enable-dp-attention 一键启用这一功效。在单节点内存受限的情形下,SGLang 团队还推出了多节点张量并行技巧。该计划容许将超年夜范围模子(如 DeepSeek V3)跨多个 GPU 或节点停止参数分区安排,无效冲破单节点内存瓶颈。用户能够依据现实资本情形,在集群情况中机动设置多节点张量并行,确保模子在高负载场景下仍然能坚持高效推理跟资本应用率。为了在推理进程中进一步均衡数值精度与盘算效力,团队还开辟了块级 FP8 量化计划。在激活值量化方面,采取 E4M3 格局,并经由过程对每个 token 内 128 通道子向量停止在线 casting,实现静态缩放,从而确保量化后激活值的数值稳固性;而在权分量化上,则以 128×128 块为基础单位停止处置,使得量化进程更为精致,无效捕获权重散布特征。这一计划已在 DeepSeek V3 模子中默许启用,为模子在高效推理的同时坚持较高精度供给了无力保证。在如斯极致的优化之下,SGLang 团队实现了从解码盘算到内存治理、从单节点优化到跨节点协同的全方位晋升。这些技巧翻新使得 SGLang 在 DeepSeek 模子在坚持高精度的基本上,其输出吞吐率最高可达 7 倍晋升,并在高并发跟年夜范围安排场景中展示出出色的机能跟机动性。更多具体技巧信息及应用案例,请参阅官方 Blog 与相干技巧演示文稿。二、Zero-Overhead Batch Scheduler:调理器的效力反动在传统推理引擎中,只管年夜模子的推理重要依附 GPU 运算,但 CPU 仍需承当批调理、内存调配、前缀婚配等大批任务。未经充足优化的推理体系每每会将多达一半的时光消耗在这些 CPU 开支上,重大影响团体机能。SGLang 始终以高效的批调理器著称,而在 0.4 版本中,团队进一步冲破,实现了近乎零开支的批调理器。这一技巧的中心在于将 CPU 调理与 GPU 盘算堆叠履行。详细来说,调理器提前一批运转,在 GPU 履行以后义务的同时,便同步筹备好下一批所需的全部元数据。如许一来,GPU 一直处于繁忙状况,无需等候 CPU 的调理成果,胜利暗藏了诸如婚配 radix cache 等较为昂贵的操纵的开支。经由过程 Nsight profiling 东西的测试表现,在持续五个解码批次中,GPU 全程坚持高负载,未呈现任何闲暇时段(注:该测试基于 Triton attention 后端,FlashInfer 后端将在后续版本中进一步优化)。借助这一优化,SGLang v0.4 可能充足发掘 GPU 的盘算潜力,在 batch size 明显的情形下,实现了相较于上一版本的显明晋升。尤其在小模子跟年夜范围张量并行场景下,这一优化后果尤为显明。该近零开支批调理技巧已默许启用,用户无需额定设置,即可享用机能上的明显晋升。三、多模态支撑:视觉与言语的协同减速在多模态利用场景中,SGLang 连续与海内外顶尖的多模态技巧团队深度配合,将进步的视觉与言语处置才能无缝集成到 SGLang 中。现无方案使得体系可能同时应答单图像、多图像以及视频义务,实现了在三年夜盘算机视觉场景中的进步机能,为后续多模态利用奠基了坚固基本。在实现上,SGLang 支撑经由过程 OpenAI 兼容的视觉 API 供给效劳。该接口可能处置纯文本输入,还能够接收交织文本、图像跟视频的混杂输入,满意庞杂利用场景下多模态数据的协同处置需要。用户无需额定开辟,即可经由过程同一的 API 挪用休会多模态推理的便捷与高效。官方供给的 benchmark 成果表现,在 VideoDetailDescriptions 跟 LLaVA-in-the-wild 数据集上,集成后的多模态模子在保障推理正确性的同时,相较于 HuggingFace/transformers 的原始实现,机能最高可晋升 4.5 倍。这一减速后果得益于 SGLang Runtime 的高效调理跟轻量化计划,使得体系在处置多范例数据时一直可能坚持较高的吞吐率。现在为止,SGLang 曾经在多模态支撑方面展现了出色的兼容性跟扩大才能,后续还将约请更多开辟者重构相干代码而且停止更多模子以致最新的 cosmos 天下模子跟 -o 流式模子的支撑。经由过程交互式的文本、图像跟视频输入,SGLang 不只年夜幅晋升了多模态义务的处置效力,同时也为现实利用场景下的庞杂数据协同盘算供给了无力的技巧保证。更多具体的应用方式跟机能数据,请参考官方技巧文档及 benchmark 讲演。四、X-Grammar:构造化天生的范式重构在束缚解码范畴,SGLang 应用了 XGrammar 体系在构造化天生方面更是实现了全新的范式重构,明显冲破了传统束缚解码的机能瓶颈。在高低文扩大方面,XGrammar 针对每条语法例则增添了额定的高低文信息检测,从而无效增加了与高低文依附相干的 token 数目。这一改良使体系在处置庞杂语法时可能更早辨认并应用规矩隐含的语义信息,从而下降懂得码进程中不用要的状况切换开支。为了高效治理多条扩大门路发生的履行状况,XGrammar 采取了基于树构造的数据构造方法,构建了长久化履行栈。该计划不只可能高效地治理多个履行栈,还能够在面临拆分与兼并操纵时坚持数据构造的稳固性跟高效性,确保全部解码流程一直流利运转。鄙人推主动机构造优欧洲杯竞猜app化方面,XGrammar 鉴戒了编译器计划中的内联优化跟等价状况兼并技巧,对主动机中的节点停止精简。经由过程增加不用要的状况节点,体系可能更敏捷地实现语法例则的婚配与转换,从而明显晋升懂得码效力。别的,为充足施展多核 CPU 的盘算才能,XGrammar188BET亚洲体育投注 对语法编译进程停止了并行化处置。语法例则的编译义务被调配到多个 CPU 中心上同时履行,不只年夜幅收缩了编译时光,也为后续多义务剖析供给了坚固的基本。综合上述各项优化办法,XGrammar 技巧的集成,使 SGLang 在 JSON 解码等束缚解码义务上实现了 10 倍的减速后果。在处置庞杂构造化数据跟东西挪用场景时,XGrammar 不只年夜幅下降懂得码耽误,还为年夜范围在线效劳供给了牢靠的机能保证。有关 XGrammar 的进一步先容,SGLang 团队已在官方博客中停止了深刻探究,相干技巧文档可供参考。五、Cache-Aware Load Balancer:智能路由的架构冲破
image credit: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model自从 DeepSeek V2 宣布以来,SGLang 团队针对 DeepSeek 系列模子的 MLA(Multi-head Latent Attention)架构停止了深度优化。这些技巧笼罩了数据并行留神力(Data Parallelism Attention)、多节点张量并行(Multi Node Tensor Parallelism)以及块级 FP8 量化(Block-wise FP8),从而在解码盘算、显存治理跟多节点协等同多个环节实现了冲破性晋升。对 Multi-head Latent Attention(MLA)的优化,团队经由过程应用权重接收从新陈列盘算步调,在保障模子表白才能的条件下,均衡了盘算与内存拜访负载,下降懂得码进程中的冗余盘算,下降了 MLA 在 Decode 进程中的盘算量。在此基本上,针对 MLA 解码核仅保存一个 KV 头的计划,SGLang 团队开辟了 Triton 解码核优化计划。该计划经由过程在统一盘算块内同时处置多个 query 头,明显增加了对 KV Cache 的内存拜访需要,从而减速懂得码流程。别的,团队联合 W8A8 FP8、KV Cache FP8 量化技巧,并开辟了 FP8 批量矩阵乘法(BMM)算子,实现了 MLA 高效的 FP8 推理。值得一提的是,MLA 与 Mixture-of-Experts(MoE)模块均已兼容 CUDA Graph 跟 Torch.compile,可能进一步下降小批量推理时的耽误。经由这些综合优化,DeepSeek 系列模子在输出吞吐率方面较上一版本实现了最高达 7 倍的减速后果。面临高并发跟大量量数据的现实利用需要,团队进一步在 MLA 留神力机制中引入了数据并行留神力技巧。该计划经由过程将差别范例的 batch(包含 prefill、decode、extend 以及 idle 状况)分辨调配给各个数据并行任务单位,使得各单位可能自力处置各自义务。待义务实现后,在 Mixture-of-Experts(MoE)层前后再停止须要的同步操纵,从而明显下降了 KV Cache 的反复存储累赘,优化了内存应用,并支撑更大量量恳求的高效处置。该优化专为高 QPS(Queries Per Second)场景计划,用户在应用 DeepSeek 系列模子时可经由过程下令参数 --enable-dp-attention 一键启用这一功效。在单节点内存受限的情形下,SGLang 团队还推出了多节点张量并行技巧。该计划容许将超年夜范围模子(如 DeepSeek V3)跨多个 GPU 或节点停止参数分区安排,无效冲破单节点内存瓶颈。用户能够依据现实资本情形,在集群情况中机动设置多节点张量并行,确保模子在高负载场景下仍然能坚持高效推理跟资本应用率。为了在推理进程中进一步均衡数值精度与盘算效力,团队还开辟了块级 FP8 量化计划。在激活值量化方面,采取 E4M3 格局,并经由过程对每个 token 内 128 通道子向量停止在线 casting,实现静态缩放,从而确保量化后激活值的数值稳固性;而在权分量化上,则以 128×128 块为基础单位停止处置,使得量化进程更为精致,无效捕获权重散布特征。这一计划已在 DeepSeek V3 模子中默许启用,为模子在高效推理的同时坚持较高精度供给了无力保证。在如斯极致的优化之下,SGLang 团队实现了从解码盘算到内存治理、从单节点优化到跨节点协同的全方位晋升。这些技巧翻新使得 SGLang 在 DeepSeek 模子在坚持高精度的基本上,其输出吞吐率最高可达 7 倍晋升,并在高并发跟年夜范围安排场景中展示出出色的机能跟机动性。更多具体技巧信息及应用案例,请参阅官方 Blog 与相干技巧演示文稿。二、Zero-Overhead Batch Scheduler:调理器的效力反动在传统推理引擎中,只管年夜模子的推理重要依附 GPU 运算,但 CPU 仍需承当批调理、内存调配、前缀婚配等大批任务。未经充足优化的推理体系每每会将多达一半的时光消耗在这些 CPU 开支上,重大影响团体机能。SGLang 始终以高效的批调理器著称,而在 0.4 版本中,团队进一步冲破,实现了近乎零开支的批调理器。这一技巧的中心在于将 CPU 调理与 GPU 盘算堆叠履行。详细来说,调理器提前一批运转,在 GPU 履行以后义务的同时,便同步筹备好下一批所需的全部元数据。如许一来,GPU 一直处于繁忙状况,无需等候 CPU 的调理成果,胜利暗藏了诸如婚配 radix cache 等较为昂贵的操纵的开支。经由过程 Nsight profiling 东西的测试表现,在持续五个解码批次中,GPU 全程坚持高负载,未呈现任何闲暇时段(注:该测试基于 Triton attention 后端,FlashInfer 后端将在后续版本中进一步优化)。借助这一优化,SGLang v0.4 可能充足发掘 GPU 的盘算潜力,在 batch size 明显的情形下,实现了相较于上一版本的显明晋升。尤其在小模子跟年夜范围张量并行场景下,这一优化后果尤为显明。该近零开支批调理技巧已默许启用,用户无需额定设置,即可享用机能上的明显晋升。三、多模态支撑:视觉与言语的协同减速在多模态利用场景中,SGLang 连续与海内外顶尖的多模态技巧团队深度配合,将进步的视觉与言语处置才能无缝集成到 SGLang 中。现无方案使得体系可能同时应答单图像、多图像以及视频义务,实现了在三年夜盘算机视觉场景中的进步机能,为后续多模态利用奠基了坚固基本。在实现上,SGLang 支撑经由过程 OpenAI 兼容的视觉 API 供给效劳。该接口可能处置纯文本输入,还能够接收交织文本、图像跟视频的混杂输入,满意庞杂利用场景下多模态数据的协同处置需要。用户无需额定开辟,即可经由过程同一的 API 挪用休会多模态推理的便捷与高效。官方供给的 benchmark 成果表现,在 VideoDetailDescriptions 跟 LLaVA-in-the-wild 数据集上,集成后的多模态模子在保障推理正确性的同时,相较于 HuggingFace/transformers 的原始实现,机能最高可晋升 4.5 倍。这一减速后果得益于 SGLang Runtime 的高效调理跟轻量化计划,使得体系在处置多范例数据时一直可能坚持较高的吞吐率。现在为止,SGLang 曾经在多模态支撑方面展现了出色的兼容性跟扩大才能,后续还将约请更多开辟者重构相干代码而且停止更多模子以致最新的 cosmos 天下模子跟 -o 流式模子的支撑。经由过程交互式的文本、图像跟视频输入,SGLang 不只年夜幅晋升了多模态义务的处置效力,同时也为现实利用场景下的庞杂数据协同盘算供给了无力的技巧保证。更多具体的应用方式跟机能数据,请参考官方技巧文档及 benchmark 讲演。四、X-Grammar:构造化天生的范式重构在束缚解码范畴,SGLang 应用了 XGrammar 体系在构造化天生方面更是实现了全新的范式重构,明显冲破了传统束缚解码的机能瓶颈。在高低文扩大方面,XGrammar 针对每条语法例则增添了额定的高低文信息检测,从而无效增加了与高低文依附相干的 token 数目。这一改良使体系在处置庞杂语法时可能更早辨认并应用规矩隐含的语义信息,从而下降懂得码进程中不用要的状况切换开支。为了高效治理多条扩大门路发生的履行状况,XGrammar 采取了基于树构造的数据构造方法,构建了长久化履行栈。该计划不只可能高效地治理多个履行栈,还能够在面临拆分与兼并操纵时坚持数据构造的稳固性跟高效性,确保全部解码流程一直流利运转。鄙人推主动机构造优欧洲杯竞猜app化方面,XGrammar 鉴戒了编译器计划中的内联优化跟等价状况兼并技巧,对主动机中的节点停止精简。经由过程增加不用要的状况节点,体系可能更敏捷地实现语法例则的婚配与转换,从而明显晋升懂得码效力。别的,为充足施展多核 CPU 的盘算才能,XGrammar188BET亚洲体育投注 对语法编译进程停止了并行化处置。语法例则的编译义务被调配到多个 CPU 中心上同时履行,不只年夜幅收缩了编译时光,也为后续多义务剖析供给了坚固的基本。综合上述各项优化办法,XGrammar 技巧的集成,使 SGLang 在 JSON 解码等束缚解码义务上实现了 10 倍的减速后果。在处置庞杂构造化数据跟东西挪用场景时,XGrammar 不只年夜幅下降懂得码耽误,还为年夜范围在线效劳供给了牢靠的机能保证。有关 XGrammar 的进一步先容,SGLang 团队已在官方博客中停止了深刻探究,相干技巧文档可供参考。五、Cache-Aware Load Balancer:智能路由的架构冲破